LLM時代のプログラミングについて


ChatGPTなどのLLM(大規模言語モデル)が世界を席巻してからもうすぐ二年が経とうとしています。文章執筆はもちろん、「翻訳」「情報収集」「悩み相談」「今夜の献立」「ぼくのかんがえたさいきょうのかのじょ」などなど…LLMは、その驚異的な応用性をもって、多岐にわたる分野で使われるようになりました。
僕が生計を立てている「プログラミング」界隈も、ここ二年でガラッと変化しました。LLMは、名前の大規模「言語」モデルにある通り、テキストに特化した機械学習モデルです。コードの生成なんてチョチョイのチョイです。
また、LLMの精度も急速に向上しています。OpenAIやAnthropicなどのAI会社は、まるで雨後のタケノコのようにポンポンと新作LLMを発表。現在のフラグシップであるGPT-4oやClaude3.5-Sonnetの精度は半端じゃなく、綺麗なWebアプリもモデルに要件を伝えるだけで作れちゃいます。
ぶっちゃけ、LLMの精度がこんなにも向上すると、自分でプログラミングするのが空しいと思うことがあります。「新しいプログラミング言語を今さら勉強しても、どうせLLMに勝てねぇんだから意味ねぇじゃん」という感じに。
そんな落ち込んでる自分を励ますために、5年後ーLLMがより普及した世界でのエンジニアの仕事について考えてみました。
結論を先に述べると、もう人間コード書かなくなるんじゃねぇかなと思ってます。
現代の作業フロー
まず、我々プログラマの現代の作業フローを考えてみましょう。
- 上司や先方から要望を受ける
- 要件からプログラムの設計をする
- 設計したプログラムを開発する
- 新しく開発したプログラムをテストする
- 新しく開発したプログラムを上司や同僚にレビューしてもらう
- レビューを基にコードを添削する
- 新しい機能をデプロイする
メッチャざっくりしてますが、こんな感じです。
今回、注目してほしいのはステップ3-6までの部分です。これ、開発と添削の繰り返しなんです。コードレビューでOKが出るまで続くフィードバックループです。
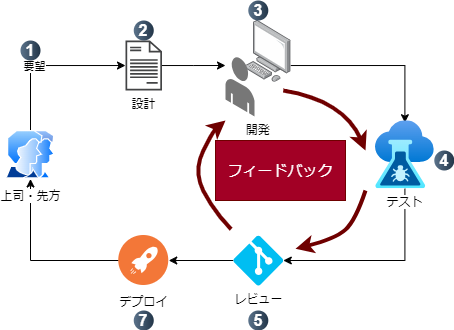
さらに厳密に言うと、テストが通るまで開発を続けるので、3と4の間にも小さいフィードバックループが存在します。
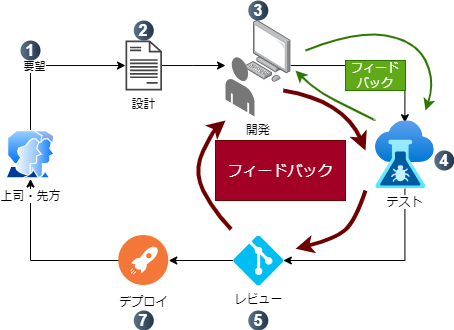
このように、現在はテストやレビューで開発状況を逐次チェックし、バグをなるべく抑える作業フローが一般的です。
LLMの作業フロー
続いて、LLMを使うときの作業フローを考えてみましょう。工程は大まかに下記の2ステップです:
- LLMに対して指示(プロンプト)を書く
- LLMが生成したものを添削(レビュー)して、修正が必要なら再度指示を出す
要は指示と添削のフィードバックループなんですね。
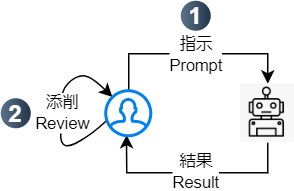
これ、開発の代わりに指示が置き換わってるだけで、本質は現代のプログラミングフローと変わらないんです。
ならば、LLMを使うときのフィードバックループを、プログラミングのフィードバックループに似せればいい、というのが私の発想です。
では、具体的にどうやってそれらを似せるのか。
ポイントとなるのは、このフィードバックが行われる「場所」です。
プログラミングしてるときに、「指示」「添削」「レビュー」「修正」する場って、すでに用意されてますよね。
そう、PR(プルリク)です。
PR画面でコードする時代
ワタクシは、5年後のプログラマーは、開発作業の大半をPR画面で費やすのではないかと考えてます。そこでやる仕事といえば、もっぱらLLMへの指示とコードレビューだと考えます。
具体的な作業フローはこんな感じです:
- 新しいBranchを作る
- 欲しい機能のテストを人間が書きPushする
- PRのコメント機能で、人間がLLMに指示を出す
- LLMが自動でコードを生成する
- LLMが自動でテストを動かし、テストが通るまで生成を続ける
- テストが通ったコードがCommitされPR画面に表示される
- 欲しい機能が全部揃うまで2-6の繰り返し
順を追って見ていきましょう。
1 - 新しいBranchを作る
これはPR作るのに必要なので省略します。
2 - 欲しい機能のテストを人間が書きPushする
この作業フローでは、まずテストを人間に書かせます。開発とテストのフィードバックループに欠かせない物ですね。
ここで書くテストには、新要素に欲しい細かい技術的な規程を予め定義します。
- HTMLエレメントのスタイル・ラベル・サイズなどなど
- コードがどれだけ早いか
- エッジケースに対応できるか
ここで人間がテストを書くことが大事になります。自分でテストを書くことで、コードの仕組みや動き方を熟考し、新機能の実装方法がイメージしやすくなります。これは後のレビュー作業で、LLMが生成したコードを理解しやすくするメリットがあります。
3 - PRのコメント機能で、人間がLLMに指示を出す
続いて、LLMにコードを書く指示を、PRのコメント機能を通じて出します。ここでは、新機能の大まかな要点をLLMに伝えます。例えばこんな感じ:
# ユーザー認証機能を実装してください
- バックエンドにはFirebaseを使ってください
- signInとsignOutのボタンをページのヘッダーに追加してください。ステップ2.で思い浮かんだ実装方法を指示に落とし込み、LLMに伝えます。
4 - LLMが自動でコードを生成する
5 - LLMが自動でテストを動かし、テストが通るまで生成を続ける
ここで、「開発」と「テスト」の小さいフィードバックループを回します。
まず、LLMがコードを生成し、それをテストにかけます。テストが通らなかった場合、テストのエラーメッセージを解読して、生成したコードを修正します。こうして、テストが通るまで、コードの生成を続けるわけです。
この「生成」と「テスト」のループは、LLMのエージェント機能を使って実装します。Agentを使うことによって、LLMに「生成」「テスト」「修正」というステップをそれぞれ連結した工程として捉えさせることができます。また、Gitやユニットテストのコマンドと、LLMの橋渡しの役割もAgentが担います。その結果、
- 「○○を実装してください、という指示が出てるのでコードを生成します」
- 「コードの生成が完了したのでテストを動かします」
- 「テストで○○が動かなかったので修正します」
- 「テストが通りました。コードをCommitします」
というように、AgentがLLMに各工程の細かい指示を渡し、フィードバックループが完成するわけです。この仕組みを実装してるプロジェクトもあるので、チェックしてみてください:
6 - テストが通ったコードがCommitされPR画面に表示される
こうしてテストを通ったコードがCommit・Pushされ、指示を出したプログラマに提示されます。プログラマは新しいコードに目を通し添削します。修正が必要な個所があればテストを書き足して、またLLMに指示を出します。こうして第二の、大きいフィードバックループが完成します。
二つのフィードバックループを通して出来上がったコードを確認し、プログラマが承認すればコードが無事Mergeされ、晴れてデプロイというプロセスになります。
こうして、プログラマはテストと指示だけ書き、LLMが実装するプログラミングフローが完成します。このフローの最後を飾るステップ6こそ、人間サイドの技量が最も試されるステップでもあります。
人間、真面目にレビューしねぇんじゃねぇか問題
皆さん、コードレビューはしっかり出来てますか?私はハッキリ言って苦手です。
自分が書いてないコードのレビューって難しいですよね。というのも、自分が書いてないので、前述した「開発←→テスト」のフィードバックループを見てないんです。よって、些細なコードの仕組み・動き方がよくわからないんですよね。
僕は、レビューを頼まれる際、新ブランチをPullして自分の環境で動かしてます。そのほうが、PR画面と睨めっこしてるより理解しやすいです。それでも機能の開発者の理解には到底及ばない。
また、PRに出されてるコードはテストをすべて通ってるので、最低限「動く」ことは保証済み。「テスト通ってるし大丈夫だろ」という気のゆるみが発現してもおかしくないです。
しかし、LLM新時代において、人間のレビューこそ肝になるんです。
「100点の製品」って、頭のヒラメキからくるものだと思うんですね。頭を柔らかくしないと出てこない。これはコードでも同じです。速く・安く・読みやすくコードを書くには斬新な発想が必要です。
それに対し、LLMは確率論によって出力を生成しています。学習データ・与えられた指示・コンテキストを総合的に吟味し、確率的に次来るであろう単語を連続して出力してるにすぎないのです。よって、LLMからは王道パターンが出力されがちです。コンスタントに85点をたたき出してるイメージです。
そして、LLMが登場して二年が経ち、その成果物がインターネットに出回ってかなりの時間が経ちました。そうすると、次世代のLLMが前世代のLLMの出力を学習する現象が始まっています。LLMが生成した王道パターンを次世代のLLMが取り込むことによって、パターンがより「王道」になり過度なバイアスがかかってく。要は頭が固くなってくるのではないかと思うわけです。
再度言いますが、LLMのコードをレビューするのは人間の仕事。LLMが生成した85点のコードを100点に引き上げるのが我々の仕事です。それを可能にするのは、王道コードから小さい改善策を見つけられる深いプログラミング知識と根気ではないかと思ってます。
終わりに
私が提案したフィードバックループって、やろうと思えばLLMが全部できちゃうと思うんですね。Agentを使って、「指示役」のLLMを用意して、そいつにテストと指示を書かせればいい。
でも、前述したバイアスの問題でそうも行かないのです。LLMは、「テストが通ること」が報酬です。「会社の利益」だったり「プロジェクトの成功」というマクロ的目標はLLMには理解できないのです。「プロジェクト」というものは「指示」や「テスト」では表現しきれない、複雑で人間臭いレベルで動いています。
人間がプロジェクトを動かすかぎり、人間の報酬系に沿ったプロジェクトを完遂するためには、これからも人間のプログラマが必要だと考えます。



